Tidyverse: R 的现代范式
R for Data Science 这本书的定位是 data science 入门书,特点是使用了 tidyverse 的一套哲学。整体思路可借用书中的一张图来说明:
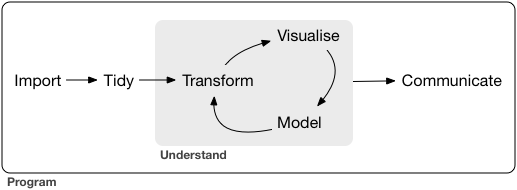
首先明确几点原则:
- 工具不是重点,创造价值才是目的。具体到数据科学,表现形式往往是提供解决方案或者做出某种决策。至于使用什么语言,采用什么工具,不本质。所以选 tidyverse 还是 pandas,用 R 还是 Python 或者是 Julia, 都可以。
- 但工具会影响单位时间内产出的效率。典型的数据分析场景下,生产力的标志可能并不是一开始就写一个保证高并发的服务框架,因为可能业务方向都还没定呢。所以这时的生产力往往是尽快发现问题,尽快验证各种模型,尽快做出合理决策。
- 好奇心往往很重要。其实想说的是,一个好的 data scientist 往往需要对新事物保持开放的心态,愿意去折腾。所以试着学一下 tidyverse 哲学应该没坏处:)
安利完毕,进入正题。
夸张一点说,作者 Hadley 真正实现了凭一己之力改变了一门语言的面貌。Tidyverse 这套哲学目的就是对 R 的旧体制做一次系统的去粗取精,这也是我将其称作 R 的新(现代)范式的原因。各个成员 package 也是尽量按照这套统一的哲学来组织,同时底层全部重新用 C++ 实现以保证速度。而为了介绍这一套,作者在本书的编排上也是花了心思,比如并不按照真实的工作流程先讲 ETL 的一套,因为太枯燥,而是先用更有意思的可视化来吸引入门者(起码别先被吓到),然后在串联起数据分析的各个模块。
关于书中各部分的建议。
- 第 I,II 部分 Explore 与 Wrangle 介绍了 dplyr,ggplot2 等重点组成部分,建议顺序阅读。
- III Program 部分主要面向初次接触 R 的人,如果之前学过则可以快速扫一遍,重点是了解下 pipeline 机制。
- IV Model 部分讲得很浅,旨在入门。重点理解下 formula 的使用,建模时很方便,而这点在其他语言里很难看到原生的支持。另外这部分最后一章中 list-columns 的形式我见的不多,在 tidyverse 框架下的使用挺新鲜,可以留意下。至于基本统计模型还是推荐去读下 An Introduction to Statistical Learning 来快速入门。
- V Communicate 则是基于 R markdown 来做各种扩展。看完会对「R 是一个完整生态」这句话有更深的理解。的确大部分时候只用它就能解决所有问题了。但依然强烈建议看完同时了解下流行的 Jupyter 等其他形式。
Hadley 几本书写下来对于如何讲问题已经很熟练了,中间的几个例子编排也很能看出其用心程度。的确,熟悉了 tidyverse 这套,做数据分析的很多事情时确实很爽,因为往往能写出非常简洁优雅的代码。但缺点也还是很突出,那就是在其他通用领域,很多时候只是够用,远不如 Python 等成熟。
这也是为什么除非你身处比较纯粹的数据或算法团队,否则,大部分工程师平时更多是在写业务代码,而中间偶尔有那么零星几点数据分析的活,此时很少有人会愿意花时间学一门新「哲学范式」。
事实上,我自己 90% 甚至更多的时间也是在写 Python,因此某些情况下,虽然明知道换到 tidyverse 更简洁方便,但生产环境中并非那么自由。所以,也请 pandas/matpoltlib/sklearn 君加油,被迫用你们时还是挺想念 tidyverse 中的很多好处的。