矩阵形式 skip-gram 算法与 TFRecord 的使用
1. 问题背景
自从 Y. Bengio 的那篇 A neural probabilistic language model 1开始,词向量一直是自然语言处理中将离散化的文字嵌入连续空间的主要方法。而随着近几年深度学习的流行,各种 embedding 的方法也成了 NLP 模型中的标配。特别是 Google 的 word2vec2发布之后,大数据量的工程化实现也不再是瓶颈。
Word2vec 的原始论文中的两种主要方法,分别是 CBOW 和 skip-gram。Google 现在主推的 TensorFlow 中将 skip-gram 算法作为例子放在了 language and Sequence Processing Tutorial 里。
在 TensorFlow 0.12.0 版本之前这部分代码仍是放在主仓库里的,目前已经被单独移到了 tensorflow/model 中,主 repo 中目前只保留了一个 word2vec_basic.py。这份 basic 版的代码用来学习 TensorFlow 基础使用是可以的,但效果和效率并不如 mini-batch 的并行版本。
其实 tensorflow/models 中的 word2vec.py 本身是并行化的版本,并且用 C++ 实现了多线程版的 skip-gram 运算,但在原始实现中输入只能是单个文件,这点并不方便。同时,C++ 实现版本中对于 batch training examples 的生成逻辑太绕,代码并不那么容易看。这也造成在 python 训练代码中需要每次判断 epoch 变量。这点如果没有看过 word2vec_kernels.cc 的代码其实开始是有点费解的。最后 checkpoint 的存储方式也并非适合所有情况,比如很多时候我们只需要最后的 word embedding 结果向量。
我一开始是用 python 模拟 word2vec_kernels.cc 的逻辑写了一份,但受限于 I/O 效率,在 4 核的 CPU 机器上都不能跑满。使用 python 自己的 threading 多线程并行则始终达不到之前的效果。于是开始尝试用 TensorFlow 自己的数据读取模式来解决。
2. TensorFlow 中 TFRecord 数据读取方法
TFRecord 本质上是基于 protobuf 的一种二进制格式,专门用于 TensorFlow 中的各种数据读写。说实话,官方文档中对于如何使用自带的 TFRecord 二进制格式进行读写操作的说明并不好,特别是对并非由图像数据入手的新手来说,很容易初看时一头雾水。这里推荐先去看一眼 tensorlayer/example 中的几个 tutorial_tfrecord*.py 的例子(当然并不推荐 tensorlayer 的代码风格)。
2.1 写入 TFRecord
TensorFlow 提供了三种基础数据类型作为 feature,分别是 BytesList / FloatList / Int64List。由这三种基础类型逐层向上构建所需训练数据的表达。大致顺序为 Feature -> Features -> Example。细节参考 tensorflow/tensorflow/core/example 下面的 feature.proto 与 example.proto。
于是你可以根据自己的需要将特定数据转化成 TFRecord 格式以进行二进制的序列化/反序列化。举一个简单的例子:
import tensorflow as tf
def _int_feature(value):
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def dump_examples_to_tfrecord(train_set, out_file):
writer = tf.python_io.TFRecordWriter(out_file)
for X, y in train_set:
example = tf.train.Example(
features=tf.train.Features(feature={
'X': _int_feature(X),
'y': _int_feature(y)
})
)
writer.write(example.SerializeToString())
writer.close()2.2 读取 TFRecord
顺序读取之前写入的 TFRecord 文件可以使用 tf.python_io.tf_record_iterator,我在 stackoverflow 上给了一个参考示例。不过这样的场景并不多,主要是在 validation set 上计算时使用。
对于训练集主要采用 TensorFlow 提供的接口。这部分还是需要仔细读下官方文档,大致分这样几个步骤:
- 由 TFRecord 二进制文件生成
File Queue; - 使用特定类型的
reader读取得到 serialized example,这里默认就是tf.TFRecordReader; - 再通过
decoder得到实际的 example,这步可使用tf.parse_sinlge_example之类的接口,通过指定features参数来完成; - 通过
tf.train.batch或tf.train.shuffle_batch等接口得到批量训练数据。
同样通过一段简单的示例代码来展示这个过程。
def read_batch_examples(file_names, N, batch_size):
file_queue = tf.train.string_input_producer(file_names)
reader = tf.TFRecordReader()
_, record_string = reader.read(file_queue)
features = {'X': tf.FixedLenFeature([N], tf.int64),
'y': tf.FixedLenFeature([1], tf.int64)}
example = tf.parse_single_example(record_string, features=features)
batch_examples = tf.train.batch(example, batch_size=batch_size)
X = batch_examples['X']
y = batch_examples['y']
return X, y其中 tf.train.string_input_producer 和 tf.train.batch 等接口都有很多方便的参数供更加细化地指定数据读取流程,比如更好的随机性和更高并发度,具体看文档接口吧。
2.3 SparseTensor 的特殊处理
可能你已经注意到了上述例子在指定 features 时使用了 tf.FixedLenFeature,这对于图像问题往往没有障碍,但在处理自然语言相关的项目时,大部分时候我们面对的是变长数据,比如一个句子。这时就需要使用 tf.VarLenFeature 了。在 TensorFlow 中 tf.FixedLenFeature 对应的是普通 tf.Tensor,而 tf.VarLenFeature 得到的则是 tf.SparseTensor。构造和使用细节还是看官方文档比较清楚:Sparse Tensor Representation。后面完整的代码中会给出详细使用的例子。
3. Skip-gram 的矩阵形式
解决了数据并行读取问题后,似乎只要对着 batch_examples 和 batch_labels 两个 Tensor 变量把 skip-gram 写一遍就好了,而且比原来更容易,也不用考虑乱七八糟的 proload buffer 或者 epoch 的处理。但事实上没有那么简单,因为 TensorFlow 的符号计算机制,循环和条件判断等都需要用专门的 tf.while_loop 或者 tf.cond。我尝试了若干种写循环的方法,但始终受制于不能有副作用的局限3,无法完成想要的 skip-gram 逻辑。最终只得另辟蹊径,这也是本文要介绍的矩阵形式 skip-gram 算法的由来。
先回顾一下 skip-gram 的思路。一个基本假定是,如果两个词语各自周围经常出现的其他词句(context)是类似的,那么这两个词语应该也是相似的。于是针对语料,我们可以无监督地得到一系列正样本对。比如下面这句话:
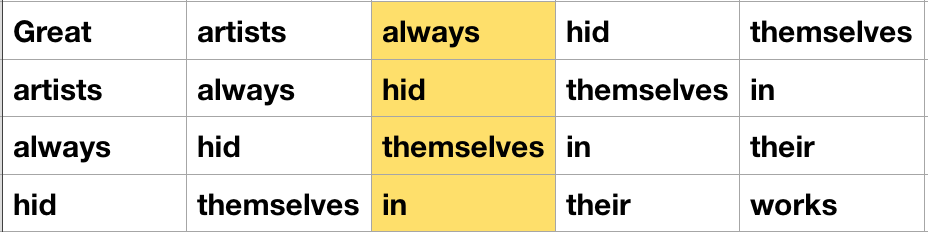
Great artists always hid themselves in their works.
如果取 window_size = 1,则可以得到如下若干样本对:
(artists, great), (artists, always),
(always, artists), (always, hid),
...
(their, in), (their, works)再利用 negative sampling 得到若干负样本,就可以愉快地使用优化算法训练了。
但是如果想不写循环得到 skip-gram 算法下的这些样本对要怎么做呢?

以 window_size = 2 为例,一种 hack 的方法是像上图这样把句子叠成一个矩阵,然后将 [i - window_size, i + window_size] 这样一个「窗口」从左向右滑动,这样就能得到每次 skip-gram 需要的局部文本。所以,接下来要做的就是使用一些 TensorFlow 提供的矩阵变换方法,得到上图中高亮区域的矩阵坐标,然后利用 SparseTensor 做转换拼接得到下图中的矩阵。
接下来就在上面这个矩阵的基础上,由中间高亮这列和其他列得到需要的样本对。代码样例如下:
def skip_gram(corpus, window_size):
span = 2 * window_size + 1
size = tf.shape(corpus)[0]
index = tf.fill([size - span, span], 1)
index = tf.concat(0, [[tf.range(0, span)], index])
index = tf.scan(lambda a, b: a + b + size, index)
index = tf.reshape(index, [-1])
M = tf.tile(corpus, [size - span + 1])
L = tf.cast(size * (size - span + 1), tf.int64)
sparse_index = tf.reshape(tf.range(0, L), [-1, 1])
M = tf.SparseTensor(sparse_index, M, [L])
X = tf.gather(M.values, index)
X = tf.reshape(X, [size - span + 1, span])
examples = tf.slice(X, [0, window_size], [size - span + 1, 1])
examples = tf.tile(tf.reshape(examples, [-1, 1]), [1, window_size * 2])
examples = tf.reshape(examples, [-1])
X_left = tf.slice(X, [0, 0], [size - span + 1, window_size])
X_right = tf.slice(X, [0, window_size + 1], [size - span + 1, window_size])
labels = tf.reshape(tf.pack([X_left, X_right], axis=1), [-1])
return examples, labels中间稍微有些 tricky 的地方,但整体就是矩阵操作,估计再仔细想下应该还有更简便的写法。这里省略了一些特殊情况的处理以及 sub-sampling 的过程,这些在完整代码中会有体现。
4. 并行训练
目前的版本中有个两个问题暂未解决。一是因为需要在训练过程中观察效果,所以程序会挑选一些词语(也可以手动指定),输出它们的相似词语。在并行训练时,由于并没有同步锁,做 normalization 和计算相似值时,同时有其他线程在写入,所以在训练初期,这些相似词语是不准的(可以观察到相似值大于 1.0)。不过这并不影响最终的结果,而且随着训练步数的增加会逐渐缓解。
另一个问题是当训练数据较大时,dump_tfrecord 这步会花费较多时间,但是由于部分 TensorFlow 中的函数无法被 pickle,所以不能直接用 multiprocessing 模块。这块暂时没有特别好的主意。
最终的训练程序借鉴了 TensorFlow 原始 word2vec.py 里多线程训练的方法。代码放在了我的 github 上,deluminator/word2vec,感兴趣的朋友可以参考。
Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of machine learning research, 2003, 3(Feb): 1137-1155.↩︎
Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.↩︎
如果你使用
tf.while_loop之类自带的控制接口完成 skip-gram 请告诉我具体做法,谢谢。↩︎