Better Intent Classification via BERT and MMS
In this article, I will give a brief introduction on how to improve intent classification using pre-trained model BERT and MXNet Model Server (MMS). Most of the work in this passage were done during last year, when I was still at my previous company — a chatbot solution provider.
1. Background
Intent classification, or intent recognition, is a core part of natural language understanding (NLU). When building a chatbot, it’s usually the very first module of the whole system, helping us to figure out what users want, like making a dentist appointment, asking a question about insurance premium, etc.
We usually formulate intent recognition as a multi-classification problem. It shouldn’t be a difficult problem in the context of supervised learning if we only have to deal with one chatbot case. However, as a chatbot service provider, when we want to scale this procedure to different business clients, there are some obstacles:
- Scarcity of labeled data. The client often have very few, sometimes even none dialogue data beforehand. Most of the time, we have to train a classifier with several or a dozen examples per intent. The shortage of training data excludes many powerful models, like deep neural network.
- Lack of transferability between different domains. The intents, i.e. those classification result labels, as well as the corpus characteristic, vary a lot since the clients are from different industries. We couldn’t simply reuse a financial chatbot model to an airline booking scenario. Hence when a new project arrives, more or less, we have to do some feature engineering and model fine-tuning manually.
Therefore, the previous workflow could achieve a reasonable high accuracy at a cost of manual data augmentation, handcraft feature engineering and classifier fine-tuning. What we want is a more scalable approach that works well in different domains and is able to get a high accuracy with very few training data.
BERT along with MMS is a possible approach to tackle this problem.
2. BERT: higher accuracy and less handcraft
Back then last year, BERT was still the go-to pre-trained model for language understanding problems. This huge general language model could provide a “good enough semantic representation” for arbitrary text, based on which a more general, domain-agnostic intent model could be built.
Replace manual features
The initial idea was to replace all handcraft features — key words, POS, regexp patterns — with BERT output, while keeping other model components fixed.
I used gluonnlp.model.bert.get_bert_model to initialize a BERT network, and set use_pooler=True to obtain a pooler vector. Another choice would be using all tokens’ outputs to conduct a new representing vector. I had tried both ways, but the difference wasn’t significant.
While several datasets were tested in this experiment, I will only demonstrate one of them here, with all the sensitive data removed.
This dataset included more than ten intents; examples per intent ranged from under 10 to more than 50.
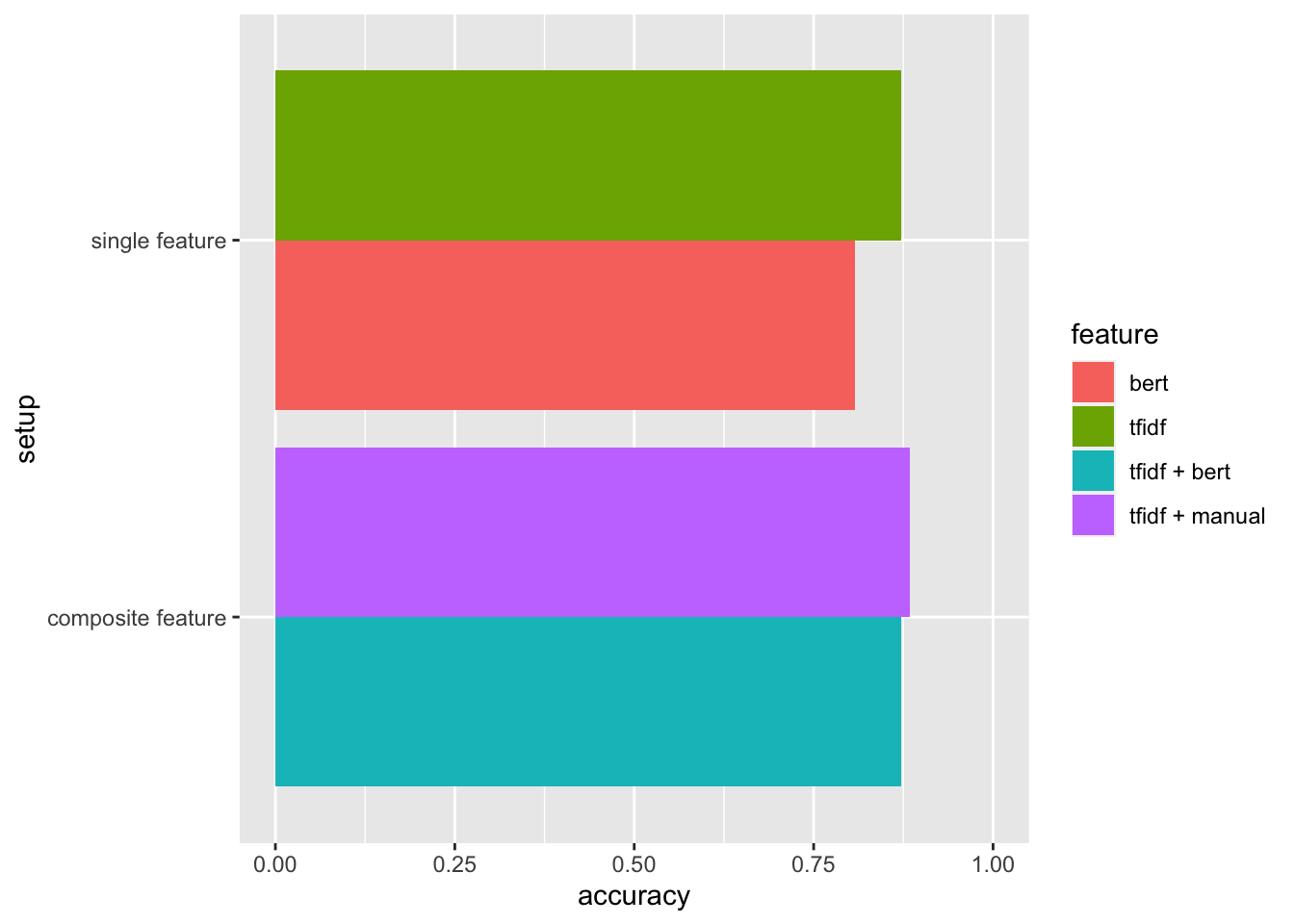
Surprisingly, using BERT as feature didn’t improve intent model’s accuracy directly, neither in single feature setup replacing tfidf, nor in composite feature setup replacing those manual ones.
Replace classifier for dense feature
Why didn’t BERT work? The reason was in the classifier. As stated before, the scarcity of labeled data forced us to use classifiers like SVM, naive Bayes, or logistic regression. These classifiers worked well on previous sparse features — tfidf, one-hot key words, etc. But they didn’t fully use BERT’s dense1 feature’s capability.
Based on this assumption, I tested a new classifier — a fully-connected dense layer2. And this setup outperformed previous results.
| feature | classifier | accuracy |
|---|---|---|
| tfidf + manual | svm | 0.884615 |
| tfidf + manual | dense | 0.897436 |
| bert | dense | 0.935897 |
| tfidf + bert | dense | 0.923077 |
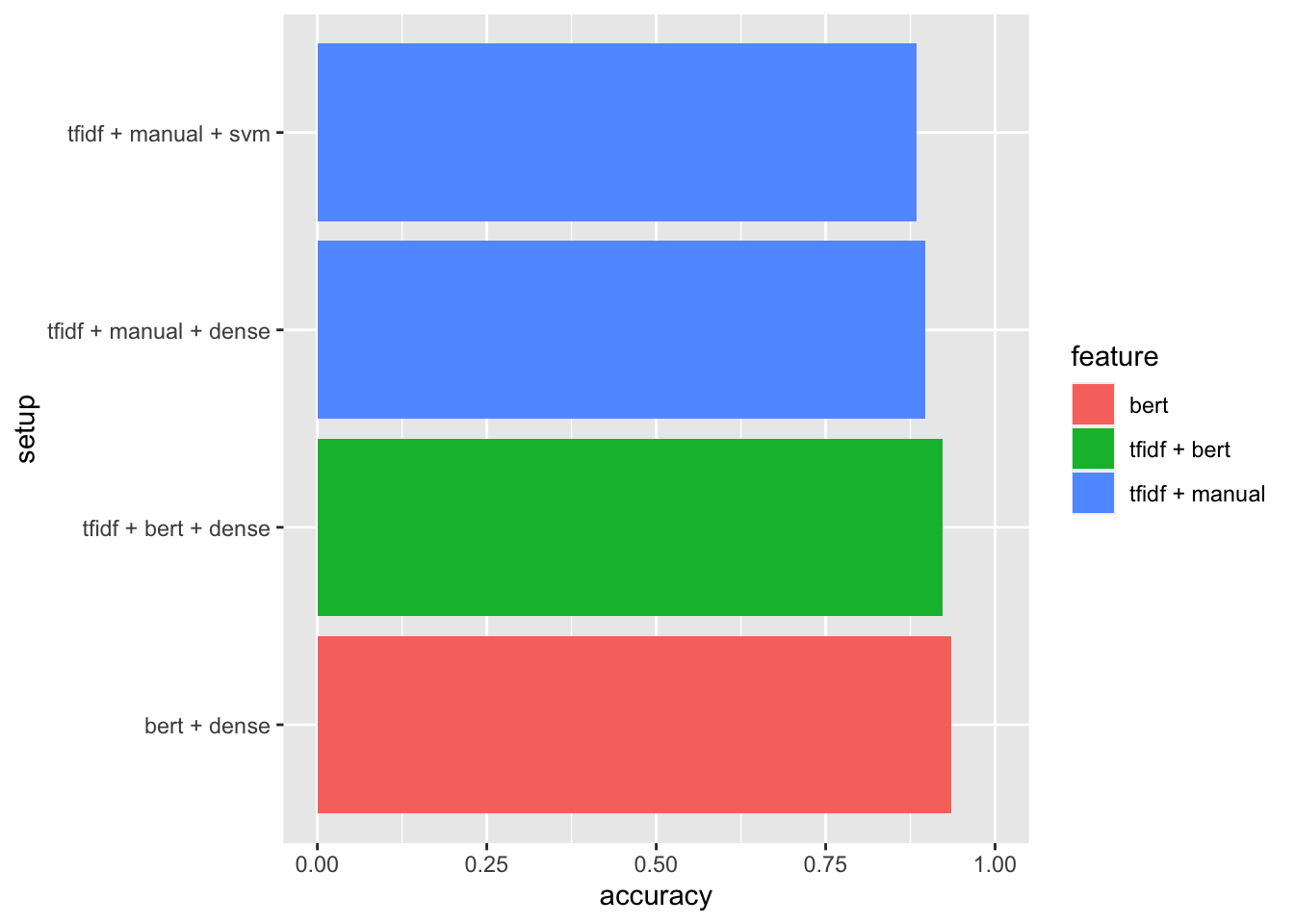
Among all the experiment datasets, pre-training method improved accuracy by several percentage points. More importantly, it helped us to get rid of manual feature engineering for every new corpus, reducing PoC projects’ cost dramatically.
3. Scaling with MXNet Model Server
Despite some private client projects, it was not a valid option to deploy BERT intent model in every chatbot:
- Huge memory usage: BERT, as well as other pre-trained language models, was very huge.
- Inference speed: many deployed instances didn’t have GPU, hence the inference speed would be slow.
- Extra dependency: deploying such a model meant introducing all the deep learning framework dependencies to client side, which was resource-consuming and hard to maintain.
Therefore, using BERT through a service was a very intuitive idea. Other teams had explored many model service options. Since we had used MXNet and gluon-nlp as deep learning toolkit already, MMS3 became a convenient choice.
Customization
There were some customization in our MMS setup. The first one was the trade off between parallel capacity and delay latency. Bigger batch size was more efficient in computing, but the backend service could be waiting as requests were coming at an unstable frequency. MMS tweaked this through batch_size and max_batch_delay — a batch of batch_size requests would be sent to backend service as long as waiting time was within max_batch_delay. Those parameters were chosen carefully based on the actual service load.
The second customization was a wrapper of gluon-nlp BERT model class. There were some special processes for out-of-vocabulary tokens in our application, therefore besides encoder tensors, we had to return input tokens and pooler vectors as well. So I created a custom mxnet.gluon.HybridBlock subclass to wrap the BERT model, and exported the hybridized model for later deploy.
Load test
I did a simple load test with ApacheBench:
ab -k -l -n 10000 -c 10 -T "application/json" \
-p test.json http://127.0.0.1:9123/predictions/bert-intent
Requests per second: 11.63 [#/sec] (mean)
Time per request: 859.758 [ms] (mean)
Time per request: 85.976 [ms] (mean, across all concurrent requests)
Transfer rate: 8346.39 [Kbytes/sec] received
3.79 kb/s sent
8350.18 kb/s totalWell, my former team had very limited and out-of-date computing resources. In this 1-card GPU server, BERT intent model would increase 86ms time per request, which was not ideal but tolerable for a chatbot application.
4. Recap
Intent classification was an essential part in chatbot system. Pre-trained language model like BERT could save most of manual feature engineering for new domain corpus, and improve classification accuracy. Meanwhile, MMS provided a practical solution for deploying huge machine learning model service.
Some special networks, like Wide-and-Deep, could get a better result on those sparse + dense features. I will discuss these issues in another post. This article only focuses on my work at my former company.↩︎
Its struture is
dense -> ReLU -> dense -> softmax.↩︎In our experiment last year, MMS was still called MXNet Model Server. Now it has been migrated to awslabs/multi-model-server.↩︎